

ACRi ルームでは AMD VCK5000 Versal 開発ボードを搭載する as005 サーバと、AMD Instinct MI210 アクセラレータを搭載する as006 サーバの無償利用環境を提供しています(詳細はこちら)。これらのサーバを利用することで、AI モデルの学習から Vitis AI によるモデルの量子化、コンパイル、実行までを行うことができます。
ROCm を使用した AI モデルの学習
ROCm は AMD GPU を使って AI などの計算を高速化するソフトウェアです。as006 サーバには ROCm がインストールされており、ROCm を利用した高速な AI モデルの学習ができます。
PyTorch のインストール方法
as006 に SSH またはリモートデスクトップでログインしターミナルを開きます。
作業ディレクトリ内に venv 環境を作成し、ROCm に対応した PyTorch をインストールするには次のようにします。
mkdir /scratch/$USER/my-pytorch-project
cd /scratch/$USER/my-pytorch-project
python -m venv .venv
source .venv/bin/activate
pip install --find-links=/tools/pip/pytorch torch==2.3.1+rocm6.0 torchvision==0.18.1+rocm6.0 torchaudio==2.3.1+rocm6.0ROCm が有効であることを確認します。
python -c "import torch ; print(torch.cuda.is_available())"あとは PyTorch を使用して AI モデルの学習を行うことができます。
ACRi ルームのサーバではインターネットへのアクセスができませんが、pip を使用した pypi.org からのパッケージのインストールはユーザーが自由にできるようになっています。例えば numpy をインストールするには次のようにします。
pip install numpyPyTorch による画像分類チュートリアル
CIFAR10 データセットの画像分類を ResNet モデルで学習するチュートリアルを実行してみましょう。as006 にログインし、スクラッチ領域にチュートリアルのリポジトリをコピーします。
cd /scratch/$USER
cp -a /tools/repo/acri-room/vai-tutorial .
cd vai-tutorialvenv 環境を作成し PyTorch をインストールします。
python -m venv .venv
source .venv/bin/activate
pip install --find-links=/tools/pip/pytorch torch==2.3.1+rocm6.0 torchvision==0.18.1+rocm6.0 torchaudio==2.3.1+rocm6.0他に必要となるパッケージをインストールします。
pip install -r requirements.txt以降の手順で問題が起きないようnumpyのバージョンを2未満にしておきます。
pip install "numpy<2"CIFAR10 データセットを data ディレクトリ以下に展開します。
mkdir data
tar xf /tools/data/cifar-10-python.tar.gz -C dataモデルを学習するには次のスクリプトを実行します。
./scripts/train.shデフォルト設定では200エポックの学習を行い、15分ほど時間がかかります。時間短縮のために8エポックだけ学習させたい場合は次のようにします。
./scripts/train.sh trainer.max_epochs=8学習中の GPU の使用状況を確認するには、別のターミナルを開いて rocm-smi コマンドを実行します。次のように出力されます。
$ rocm-smi
======================================= ROCm System Management Interface =======================================
================================================= Concise Info =================================================
Device [Model : Revision] Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU%
Name (20 chars) (Edge) (Avg) (Mem, Compute)
================================================================================================================
0 [0x0c34 : 0x02] 51.0°C 222.0W N/A, N/A 1675Mhz 1600Mhz 0% auto 300.0W 12% 100%
Instinct MI210
================================================================================================================
============================================= End of ROCm SMI Log ==============================================学習の進み具合は TensorBoard を使用して確認できます。TensorBoard を起動するには別のターミナルを開いて次のようにします。
cd /scratch/$USER/vai-tutorial
source .venv/bin/activate
tensorboard --logdir ./logs/train/runs/リモートデスクトップで as006 に接続し、Firefox または Chrome で http://localhost:6006 を開くと TensorBoard の画面にアクセスできます。学習が進むにつれロスが下がり精度が上がっていることが分かります。
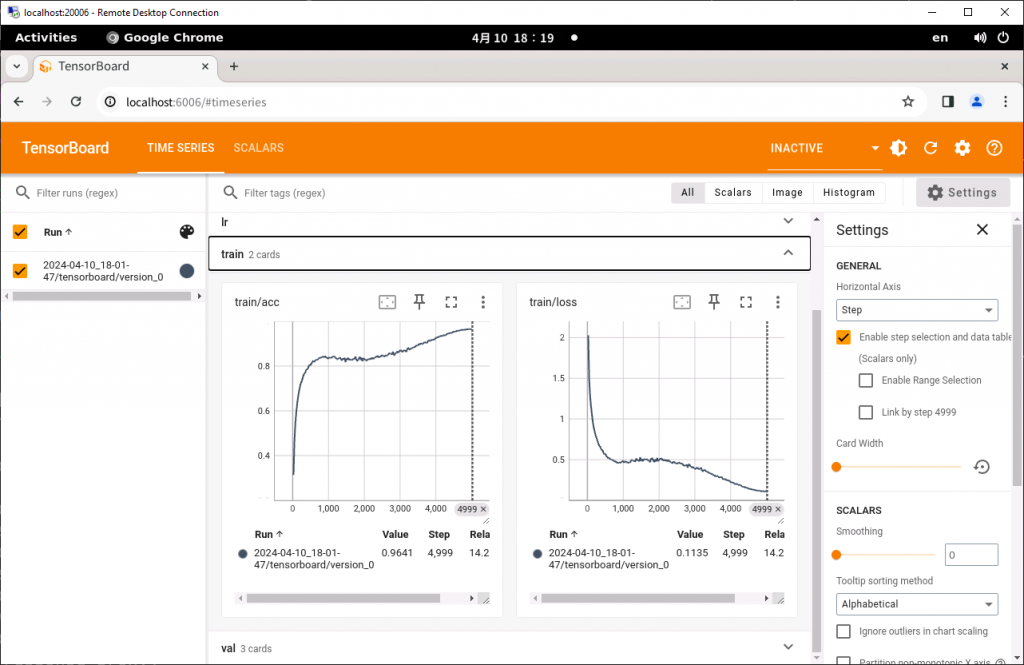
200エポック学習させたときの精度は95.1%となりました。
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ DataLoader 0 ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ test/acc │ 0.9510999917984009 │
│ test/loss │ 0.1570771187543869 │
└───────────────────────────┴───────────────────────────┘Vitis AI による量子化、コンパイル
Vitis AI による量子化は GPU により高速に行うことができます。上記のチュートリアルで学習したモデルを量子化、コンパイルしてみましょう。学習済みのモデルは ./logs ディレクトリの下に保存されています。
./logs/train/runs/2024-04-10_18-01-47/checkpoints/
├── epoch_196.ckpt
└── last.ckptこの例ではテスト用のデータセットに対する精度が最も高かったモデルが epoch_196.ckpt として保存されています。以降の手順ではこのファイルを対象に量子化を行います。
量子化の手順
Vitis AI の PTQ (Post Training Quantization) による量子化の手順は次のとおりです。
- キャリブレーション
- モデルにデータを入力し、各層の出力の分布を調べることで量子化係数を決定します
- テスト
- 量子化後のモデルの精度を確認します
- デプロイ
- 量子化したモデルを xmodel 形式でエクスポートします
- xmodel ファイルはコンパイラへの入力になります
Vitis AI による量子化は正式には Docker 環境で行いますが、公式の Docker イメージにインストールされている PyTorch のバージョンが古いため、ここでは Docker は使用せず量子化に必要なツールをソースコードからビルドして使用します。次のコマンドでビルドを実行します。
cd /scratch/$USER/vai-tutorial
source .venv/bin/activate
./scripts/build_quantizer.shキャリブレーションを実行します。ckpt_path= のパスはご自身の環境に合わせて変更してください。
./scripts/quant_calib.sh ckpt_path=./logs/train/runs/2024-04-10_18-01-47/checkpoints/epoch_196.ckpt量子化に関する情報は quantized ディレクトリ以下に保存されます。
次に量子化後のモデルの精度をテストします。
./scripts/quant_test.sh ckpt_path=./logs/train/runs/2024-04-10_18-01-47/checkpoints/epoch_196.ckpt量子化前の95.1%からわずかに下がり94.7%となりました。問題ないためこのまま進めます。
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ DataLoader 0 ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ test/acc │ 0.9473000168800354 │
│ test/loss │ 0.16378344595432281 │
└───────────────────────────┴───────────────────────────┘最後にモデルを xmodel 形式でエクスポートします。
./scripts/quant_deploy.sh ckpt_path=./logs/train/runs/2024-04-10_18-01-47/checkpoints/epoch_196.ckpt./quantized/ResNet9_int.xmodel に量子化したモデルが保存されます。
コンパイルの手順
Vitis AI のコンパイラはオープンソースではないため Docker 環境から使用する必要があります。as006 および as005 では Rootless Docker をセットアップすることでユーザーが Docker を利用できます。
Rootless Docker のセットアップ方法
初めて Rootless Docker を使用する際に以下を実施する必要があります。
1. Rootless Docker の設定ファイルを作成します。
mkdir -p ~/.config/docker
echo "{ \"data-root\" : \"/docker-data/$(id -un)\" }" > ~/.config/docker/daemon.json2. Rootless Docker をインストールします。
dockerd-rootless-setuptool.sh install上記を実施しても Docker デーモンに接続できない場合は次のようにしてサービスの再起動を行ってみてください。
systemctl --user restart docker.serviceDocker イメージのロード
Vitis AI の Docker イメージをロードします。モデルのコンパイルには GPU は使用しないため CPU のみのイメージを使用します。これには2分ほど時間がかかります。
docker load -i /tools/docker/xilinx/vitis-ai-pytorch-cpu/ubuntu2004-3.5.0.306.tardocker images コマンドでイメージがロードされたことが確認できます。
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
xilinx/vitis-ai-pytorch-cpu ubuntu2004-3.5.0.306 10667a5b7322 9 months ago 11.7GBDocker コンテナを立ち上げるには次のスクリプトを実行します。
./docker/run.shうまく立ち上がると次のように表示されます。
==========================================
__ ___ _ _ _____
\ \ / (_) | (_) /\ |_ _|
\ \ / / _| |_ _ ___ ______ / \ | |
\ \/ / | | __| / __|______/ /\ \ | |
\ / | | |_| \__ \ / ____ \ _| |_
\/ |_|\__|_|___/ /_/ \_\_____|
==========================================
Docker Image Version: ubuntu2004-3.5.0.306 (CPU)
Vitis AI Git Hash: 6a9757a
Build Date: 2023-06-26
WorkFlow: pytorch
root@as006:/workspace# xmodel 形式のモデルのコンパイルには vai_c_xir コマンドを使用します。VCK5000 をターゲットにコンパイルするには次のようにします。
vai_c_xir \
--xmodel ./quantized/ResNet9_int.xmodel \
--arch /opt/vitis_ai/compiler/arch/DPUCVDX8H/VCK50008PE/arch.json \
--output_dir ./compiled \
--net_name ResNet9_Cifar10VCK5000 向けの DPU 実装は PE のインスタンス数やサポートレイヤーの違いから以下のバリエーションがあります。使用したい DPU 実装に合わせて上記コマンドの --arch オプションへ渡すパスを変更してください。
| DPU アーキ | PE 数 | タイプ | arch.json のパス |
|---|---|---|---|
| DPUCVDX8H | 4 | miscdwc | /opt/vitis_ai/compiler/arch/DPUCVDX8H/VCK50004PE/arch.json |
| DPUCVDX8H | 6 | dwc | /opt/vitis_ai/compiler/arch/DPUCVDX8H/VCK50006PEDWC/arch.json |
| DPUCVDX8H | 6 | misc | /opt/vitis_ai/compiler/arch/DPUCVDX8H/VCK50006PEMISC/arch.json |
| DPUCVDX8H | 8 | normal | /opt/vitis_ai/compiler/arch/DPUCVDX8H/VCK50008PE/arch.json |
特に問題がなければ ./compiled ディレクトリ以下にコンパイル後のモデルが出力されます。Docker コンテナは閉じてしまって構いません。
コンパイルされたモデルがどのように DPU に割り付けられたかを Netron を使って確認します。ホスト側のターミナルに戻り、次のコマンドを実行します。
cd /scratch/$USER/vai-tutorial
source .venv/bin/activate
netron ./compiled/ResNet9_Cifar10.xmodelリモートデスクトップのブラウザで http://localhost:8080 を開きます。
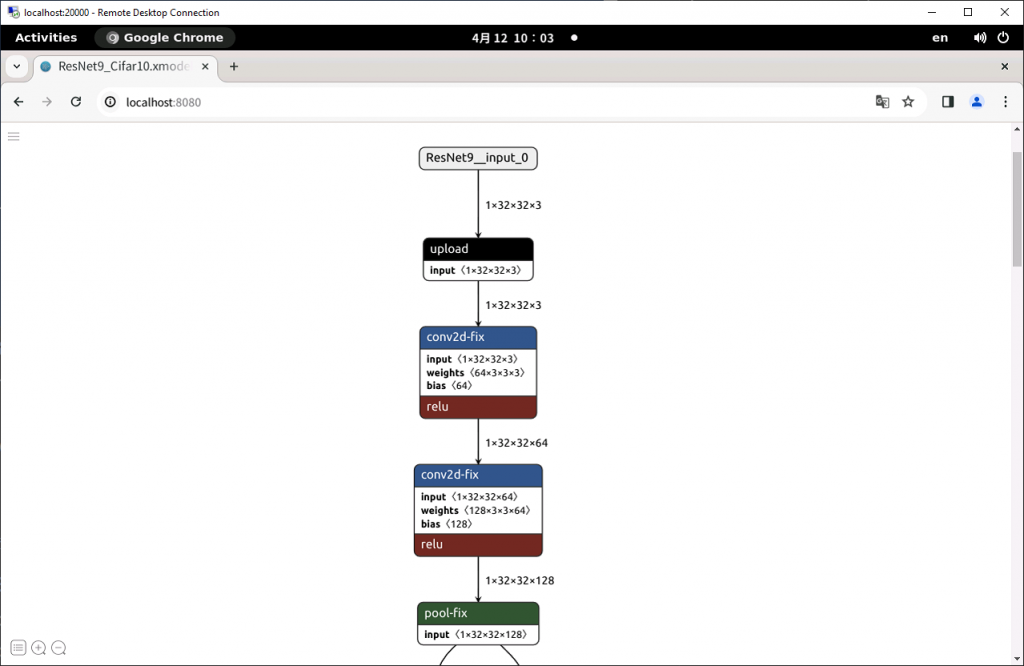
upload と download はホストとデバイスの間のデータ転送を意味します。モデルの中に DPU がサポートしていないレイヤーが含まれているとホスト CPU で処理する必要があり、余計なデータ転送が発生してしまいます。今回使用したモデルの元の実装では nn.MaxPool2d(4) が使用されていてこれに DPU が対応していなかったため、連続するふたつの nn.MaxPool2d(2) に置き換えることで対策しました。
Vitis AI によるモデルの実行
Vitis AI で量子化、コンパイルしたモデルを VCK5000 で動作させてみましょう。ここからは as005 にログインして作業を進めます。
as005 のスクラッチ領域にチュートリアルのリポジトリをコピーします。
cd /scratch/$USER
cp -a /tools/repo/acri-room/vai-tutorial .
cd vai-tutorialvenv 環境を作成し、PyTorch をインストールします。as005 では GPU は使用できないため CPU 版のPyTorch を指定します。
python -m venv .venv
source .venv/bin/activate
pip install --find-links=/tools/pip/pytorch torch==2.2.2+cpu torchvision==0.17.2+cpu torchaudio==2.2.2+cpu他に必要となるパッケージをインストールします。
pip install -r requirements.txtモデルの実行に必要となる Vitis AI Runtime 関連のソフトウェアをビルドします。
./scripts/build_runtime.shターゲットの DPU 実装を指定するための環境設定を行います。
source ./docker/setup_vck5000.sh DPUCVDX8H_8pe_normal最後の引数にはコンパイル時に指定した DPU 実装を次の中から指定します。
- DPUCVDX8H_4pe_miscdwc
- DPUCVDX8H_6pe_dwc
- DPUCVDX8H_6pe_misc
- DPUCVDX8H_8pe_normal
as006 でコンパイルしたモデルを as005 にコピーします。予約不要の as106 が as006 とスクラッチ領域を共有しているためこれを利用します。
scp -r as106:/scratch/$USER/vai-tutorial/compiled .入力データとして CIFAR10 データセットを展開します。
mkdir data
tar xf /tools/data/cifar-10-python.tar.gz -C data以上でモデルを実行する準備が整いました。
次のように xmodel= にコンパイルしたモデルのパスを渡して実行します。初回は少し時間がかかります。
./scripts/run.sh xmodel=./compiled/ResNet9_Cifar10.xmodel成功すると次のように表示されます。ターミナルによって画像がうまく表示されない場合はリモートデスクトップで接続して Ubuntu のターミナルから実行してみてください。

より多くの結果を確認したい場合は num_batches= オプションを指定します。
./scripts/run.sh xmodel=./compiled/ResNet9_Cifar10.xmodel num_batches=100生成 AI を動かすための環境設定
従来禁止されていた ACRi ルームからインターネットへのアクセス制限を緩和し、生成 AI を気軽に試せる環境を整えています。as006 / as106 サーバーではあらかじめ環境変数が設定されているため、ユーザーが特に何も設定しなくても HTTP プロキシサーバーや pip ミラーサーバー、HuggingFace ミラーサーバー(試験運用)が利用できます。
エラーが起きるなどの理由でミラーサーバーを無効にしたい場合は環境変数をクリアしてください。
# pip ミラーサーバーを無効にするとき
unset PIP_INDEX_URL
# HuggingFace ミラーサーバーを無効にするとき
unset HF_ENDPOINTDocker のプロキシ設定
Docker イメージのビルド時やコンテナ内からインターネットにアクセスできるようにするには各自で HTTP プロキシサーバーの設定を行う必要があります。Rootless Docker のセットアップが済んでいない場合は先にこちらの手順を実施してください。systemctl edit docker を実行し以下を入力し保存してください。
[Service]
Environment = "http_proxy=http://172.16.2.9:3128" "https_proxy=http://172.16.2.9:3128" "no_proxy=localhost,127.0.0.1,172.16.2.9"保存できましたら設定を反映するために systemctl --user restart docker.service を実行してください。
Miniconda の利用方法
Miniconda を利用するには次のようにしてインストールします。
mkdir /scratch/$USER/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /scratch/$USER/miniconda.sh
bash /scratch/$USER/miniconda.sh -b -u -p /scratch/$USER/miniconda3
rm /scratch/$USER/miniconda.shMiniconda を有効化、環境を作成しアクティベートするには例えば次のようにします。
source /scratch/$USER/miniconda3/bin/activate
conda create --name openllm_env python=3.11
conda activate openllm_envvLLM を動かす手順
ROCm ブログのこちらの記事で紹介されている vLLM を動かす方法を ACRiルームでも試してみます。Docker イメージをビルドする手順を含むため、上記の Docker の環境設定を済ませておいてください。

as006 または as106 にログインしてください。ROCm 環境向けの vLLM を Docker を使用してビルドします。作業領域へ移動し、リポジトリをクローンします。
cd /scratch/$USER
git clone https://github.com/vllm-project/vllm.git && cd vllmブログ記事にあるようにDockerfile.rocmを修正します。
cat << EOS | patch -p1
diff --git a/Dockerfile.rocm b/Dockerfile.rocm
index db785090..4a80789b 100644
--- a/Dockerfile.rocm
+++ b/Dockerfile.rocm
@@ -245,5 +245,15 @@ ENV TOKENIZERS_PARALLELISM=false
# Performance environment variable.
ENV HIP_FORCE_DEV_KERNARG=1
+# Installing OpenLLM and additional Python packages
+RUN python3 -m pip install openllm==0.4.44
+RUN python3 -m pip install -U pydantic
+
+#Setting the desired visible devices when running OpenLLM
+ENV CUDA_VISIBLE_DEVICES=0
+
+# OpenLLM server runs in port 3000 by default
+EXPOSE 3000
+
CMD ["/bin/bash"]
EOSDocker イメージをビルドします。
docker build -t openllm_vllm_rocm -f Dockerfile.rocm .ビルドには1時間近くかかります。ビルドしたイメージはサーバーの再起動で消えてしまうため、また使用する可能性がある場合はディスクに保存しておくと良いです。
docker save openllm_vllm_rocm -o /scratch/$USER/openllm_vllm_rocm.tar次回以降、保存したイメージを読み込むには次のようにします。
docker load -i /scratch/$USER/openllm_vllm_rocm.tarイメージがビルドできたら次のようにしてコンテナを起動します。
docker run -it --rm -p 3000:3000 --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --shm-size 8G -v $(pwd):/root/bentoml -v /scratch/$USER/.cache/huggingface:/huggingface openllm_vllm_rocm上記のコマンドではブログ記事のコマンドに -v /scratch/$USER/.cache/huggingface:/huggingface を加えて、作業領域にキャッシュされたモデルが使用されるように工夫しています。
コンテナ内に入ったら、モデルのキャッシュディレクトリを環境変数で設定して、コンテナ内のユーザーが GPU を使用できるように render グループに追加します。
export HF_HOME=/huggingface
usermod -a -G render,video root
newgrp render元の記事では OpenLLM を動かす内容になっていましたがエラーが出てしまいましたのでここでは vLLM の OpenAI 互換 API サーバーを動かします。使用するモデルには CyberAgentLM3-22B-Chat を指定しています。
python -m vllm.entrypoints.openai.api_server --host "0.0.0.0" --port 3000 --model cyberagent/calm3-22b-chat --max-model-len 8192特にエラーがなければホスト側のターミナルをもうひとつ開き、テストのための venv 環境を作成し、必要なパッケージをインストールします。
mkdir /scratch/$USER/vllm-test
cd /scratch/$USER/vllm-test
python -m venv venv
source venv/bin/activate
pip install openai次の内容で test.py を作成します。
import os
from openai import OpenAI
client = OpenAI(base_url=os.environ['OPENAI_API_BASE'])
completion = client.chat.completions.create(
model="cyberagent/calm3-22b-chat",
messages=[
{"role": "system", "content": "あなたは親切なAIアシスタントです。"},
{"role": "user", "content": "FPGAのエクストリームな使い方のアイディアを3つ挙げてどのようにエクストリームか説明して。"}
],
stream=True,
temperature=0.8,
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
print()上記コードを実行するための環境変数を設定します。
export OPENAI_API_KEY=EMPTY
export OPENAI_API_BASE=http://localhost:3000/v1test.py を実行すると次のような出力を得られます。
$ python test.py
FPGA(フィールド・プロプーツ・ゲート・アレイ)は非常に強力なハードウェアプラットフォームで、さまざまなエクストリームな使い方があります。以下に3つのアイディアを挙げ、それぞれがどのようにエクストリームか説明します。
1. 量子コンピューティングのエミュレーション:
- アイディア: FPGAを用いて特定の古典的なハードウェアで量子コンピュータの動作をエミュレーションする。
- エクストリームな点: 量子ビット(キュービット)の動作を古典的なFPGAで再現するために、数百万から数十億のトランジスタを使用する可能性があります。これにより、量子ゲートの複雑な動作、エンタングルメント、量子干渉など、量子コンピュータの基本的な動作原理をシミュレーションできます。このシミュレーションは、量子コンピ ューティングの研究やアルゴリズムの開発において非常に重要なステップとなります。
2. リアルタイム画像解析と処理:
- アイディア: FPGA上でリアルタイムに高解像度の画像解析を行うシステムを構築。
- エクストリームな点: 最高水準の精度と速度でリアルタイムの画像解析を実現するために、数百万個のトランジスタを使用することができます。医療診断、自動運転車、ロボティクスなどで必要となる複雑なアルゴリズムを高速で処理するために、画像データの前処理、フィルタリング、特徴抽出、物体認識などをFPGAで直接実行します。これ により、遅延の少ないリアルタイム解析が可能となります。
3. 大規模カスタム通信システム:
- アイディア: 特注の超高速通信プロトコルをFPGA上で動作させる。
- エクストリームな点: 極めて高速なデータ通信を実現するために、FPGA上で複雑なプロトコルやデータ変換ロジックを実装します。例えば、50 Gbps以上のデータレート で動作するカスタムプロトコルを設計し、それに伴う最適化やエラー訂正ロジックも含めます。このシステムは、400Gや800G級の高速インターネットバックボーンや、科学研 究用のデータ伝送システムなど、現在の標準的な通信インフラを超える性能を提供します。
これらのアイディアは、FPGAがその限界まで使用されるシナリオを提示しており、さまざまな分野での革新を促進する可能性があります。